
プロフィール

BlueTrain
茨城県
プロフィール詳細
カレンダー
検索
タグ
アーカイブ
アクセスカウンター
- 今日のアクセス:201
- 昨日のアクセス:181
- 総アクセス数:1399126
QRコード
▼ 釣りのためのデータサイエンス 実際の分析 前処理地獄編
- ジャンル:日記/一般
しばらくやっていなかった、「釣りのためのデータサイエンス」シリーズ。
P値や相関分析、因果推論なんかを本当に軽ーく触った気がします。
じゃあ実際やってみっぺ。
実際にデータサイエンスを釣りに落とし込もうと思ったらかなり主観的なところから始まります。
自分はこう思う、という仮説が一番大事になってきます。
それをデータと照らし合わせて、仮説を立ててもいいかどうか?を調べるのがデータサイエンスになるかと思います。
じゃあ実際に自分の仮説を立ててみます。
自分の仮説
「ヒラメは夜に浮いて波で打ち寄せられたイワシを追いかけて、夜にサーフに接岸する。そして昼になるとイワシは抜けていく。またヒラメは回遊遅れが存在し、荒れている日は早く抜けて凪の日は長くサーフに居る。」
まずこの仮説を否定しようと思います。
これが結構大事で折角立てた自分の仮説を否定するのはしんどいです。
まぁやってみます。
1,ヒラメは波で打ち寄せられたイワシを追いかけていない。
2,夜にヒラメは接岸していない。
3,昼になっても釣果は変わらない。
4,回遊遅れは存在しない。
5,荒れている日と凪の日でも釣果に差はない。
一個一個見ていくと、まず除外して良い否定があってヒラメがイワシを追いかけていたり、荒れている日より凪の日の方がいいのはデータから明らか。
ここで夜に浮いたイワシの話は有名な論文があるので科学的な確度は高いので調べることはしません。
本当はそれも再現度と解釈があっているかどうかも確かめた方が良いですが、夜にベイトが浮くのは結構共通した性質なので省略します。
知りたいのは夜にヒラメが接岸してきたりするのか、昼になっても釣果は変わらないのか、回遊遅れは存在しないのか、などが分析対象になるかな、と思います。
ではここで、結構論理を飛躍させて(これが大事)荒れている日はヒラメの抜けは早い、と仮説を立てます。
これを釣果データから見て、朝まずめの時間が短くなっていれば自分の仮説は少し証明された、と言えるでしょう。
実は今書いた2行くらいにはかなり省略された文があります。
まず、ヒラメをベントスと仮定してサーフが荒れている時は回遊性が高い、という仮説が含まれています。
これは専門書から引用した文章で、大型の底生物は逸散型のサーフには存在せず、回遊性の高い生き物しか居なくなる、と書いてあります。
これも一方の面からの解釈なので本当は吟味する必要がありますが、まぁ大体想像つくのでこれで良いっていう下に分析を始めちゃうわけです。
こういうところを一個一個大事やっていくのが科学なのですが、釣りで分析するのには大胆な仮説を進めて根本からゆらいで間違っていたとしても大してダメージ無いだろ、というのがあるのでここら辺は折りこんじゃってます。
こういうところを考えても、ヒラメのベイトはイワシだけだ、っていうのを科学の話からするのはドエラい大変さが伴うのは間違いないです。
じゃあ、まぁそれでいい、っていうことにして分析を始めます。
今回もひらめっぱりさんからデータをお借りして、荒れている日と凪の日の朝まずめの釣果データを調べたいと思います。
ひらめっぱりさんのデータには荒れている日のデータは無いので、見つけて来なければなりません。
そしてその後、気象データと釣果データを合体(マージ)させて分析します。
https://www.data.jma.go.jp/kaiyou/db/wave/chart/wavepoint/wave_point.html?point=4&year=2023&month=6
波のデータは気象庁からCSVでダウンロードできました。
ここで、荒れている、とはどんな基準で決めたらいいのでしょうか。
風や波の高さ、周期は荒れに関係しています。
ここではとりあえずやってみておおまかな結論だけ得たいので、波の高さを4分割くらいにして釣果データをグルーピング(グループにする)にしてみたいと思います。
ここからChatGPTの力を借ります。
GPT-4はかなり強力にコーディングが出来ますが、結局コードが自分で書けるくらいの能力が無いと何が原因で動かないか分からない、という事は頻発します。
コピペを繰り返せば出来なくも無いですが、それよりも一行ずつ自分で考えたのものをChatGPTに書いてもらう形式で書きました。
Rを使ってひらめっぱりさんから借りてきたデータを処理します。
まず、日付が文字データなので日付データに直します。
次に、気象庁から持ってきたデータの日付と釣果の日付が同じならその時の波のデータを釣果データにつけたします。(マージ)
次に、釣れた時間の何時のデータだけを取り出し、数値に置き換えます。
最後に、波の大きさを四分位数に分けてカテゴリカルにします。
ここまででかなりの時間を消費。
頭の中ではこういうのはやる前に完成しているんだけど、実際にやろうとすると、半角のデータの中に全角が入っていたり、入力規則が違っていたりして、それを見つけて除外したりするので結構大変。
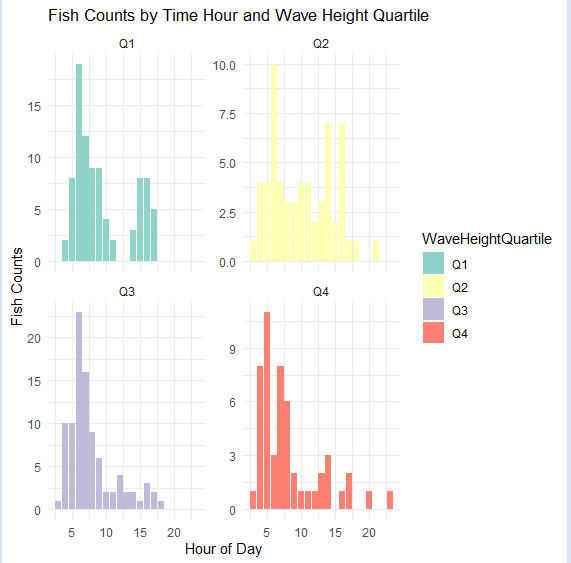
分かりやすいようにグラフにしてみました。
これは2022年の釣果データです。
Q1というのが波が一番低いグループの釣果です。
順に、Q4が一番高いです。
横軸が時間で例えば20というのは20時ということです。
縦軸がその時間の釣果数です。
これを見るとQ3のグループは一番釣れていますが、午後になると殆ど釣れていません。
しかし、ある程度波の低いグループであるQ1とQ2は午後でも多少釣れているように思います。
ただ、データサイエンス的にはこれで結論を下すことはちょっとできないかなぁ、と思います。
グラフでこの300くらいのデータ数を見ただけでは科学的とまでは言えません。
自分の仮説には肯定的な結果ではありますが。
どうしたらデータだけでそう言えるのかを考えると、
「中心極限定理」という統計上の大きい定理があって、もう少しデータがそろってくるときれいな曲線になってきます。
今回は2022年だけでやりましたが、もっと年数を増やすと良いでしょう。
この記事の内容を少しまとめると、釣りをデータサイエンスに落とし込んで楽しむのには
・仮説を立てる(大事)
・仮説から言えそうな事をピックアップする
・仮説段階では夢を見ながら大胆に、大雑把にストーリーを作る
・データを集める(最高に大事)
・分析結果は冷静に見つめる
やり方の手段はChatGPTに聞けばいいです。
データを集める事に関して少し言及すると、最近第一生命が福利厚生事業の会社を3000億円以上で買収する話が出ていました。
福利厚生というのはビッグデータを持っているので、生命保険会社はアクチュアリーなどのデータに強い人がいるのでそういうデータが欲しいのではないか、と言われています。
そのくらいデータというのは現代において価値があります。
それを考えると、ひらめっぱりさんに投稿してくれているアングラー様とそれを公開してくれているひらめっぱりさんには頭が下がります。
実際の分析をやってみましたが、データが前処理さえ出来ていれば他にも色んな分析は簡単にできるので、例えば機械学習でやってもいいし、検定なんかやってみても良いと思います。
おわり
- 2024年2月20日
- コメント(0)
コメントを見る
fimoニュース
登録ライター
![]()
- フィッシングショー大阪2026行…
- 2 日前
- ねこヒゲさん

- ラッキークラフト:LV-0
- 5 日前
- ichi-goさん
![]()
- 『秘策!ステルス作戦』 2026/…
- 14 日前
- hikaruさん
![]()
- 新年初買
- 19 日前
- rattleheadさん
![]()
- 温室育ち24セルテ、逆転す
- 22 日前
- 濵田就也さん
本日のGoodGame
シーバス
-

- '25 これぞ湘南秋鱸、大型捕獲♪
- ハマケン
-

- 流れの釣り
- Kazuma









最新のコメント